觉得你认为难,是因为你说你不是编程高手,便成功高手想学什么都能学云云的
另外在美国学术圈小小接触之后,感觉水还是很深的。 里面 有论文利益之类的。
还有我看了一下 Julia 写的 python 排序代码。
def qsort_kernel(a, lo, hi):
i = lo
j = hi
while i < hi:
pivot = a(lo+hi) // 2]
while i <= j:
while a* < pivot:
i += 1
while a[j] > pivot:
j -= 1
if i <= j:
a*, a[j] = a[j], a*
i += 1
j -= 1
if lo < j:
qsort_kernel(a, lo, j)
lo = i
j = hi
return a
我从他的测试代码里复制的。 我就问问为什么不直接用内置的排序函数?
真的性能很好,为什么这么搞小动作?
我看了作者的解释,说如果直接用内置的排序函数,那就是和 C 比较了,不是和 R、matlab 比较……
这么解释,那我也就无语了。
Python、Matlab 之类的语言,很多计算功能都提供了直接的函数,这些都是用 Fortran、C 实现的,性能非常出色。 他们的意义就是在于你不需要自己写 C 代码了,直接用科学计算的函数,就可以快速运算出结果了。 至于语言本身,速度确实有限,但是问题在于你真正处理大量数据的部分都用函数了,他本身的那部分都是耗时忽略不计的部分了。
明明有现成、高效的排序函数不用,非要这样去写……
Julia 的语言设计似乎还凑合吧。 F# 的设计是非常优雅的。
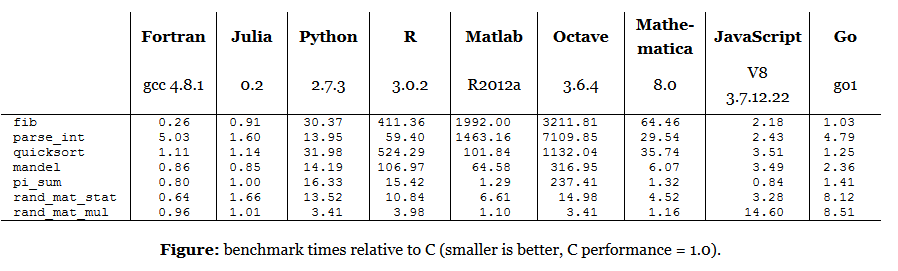
别的代码我看不懂,比如说 mandel,你们学科学的应该懂。我不懂,我主要做离散数学的。 但是就看他的 R 代码一堆 for 循环。 很多人质疑他的测试不公平,拿出更好的代码,作者就说你这个改进是改进了算法,不算,比较无效。有人又提出他的 R 代码故意用的 R 最不擅长的方式写的,结果作者又提出自己对计算 fib 没兴趣,不关心,无意重写……
再看他的 C 语言 fib 数,我不写 C,但是看出他是递归算的。 C 语言是标准的低级语言,一般都是迭代计算的,他非要写个递归:
int fib(int n) {
return n < 2 ? n : fib(n-1) + fib(n-2);
}
这个代码的意思就是说对 fib(n) 计算,计算 fib(n-1) 再计算 fib(n-2),然后加起来。
你自己想想看了, 假设计算 fib(100),他这个代码就算 fib(99)+fib(98),然后算 fib(99) 又计算 fib(98)+fib(97)
如果你算 fib,那么这样算,就这一层 fib98 就重复计算了。 那么多层,重复计算多少次?
C 语言不是致力于递归计算的语言,C 语言要写 fib,正确写法是
我不会 C,所以就写伪代码了:
fib 0 = 0
fib 1 = 1
for i=2 to n
fib i = fib (i-1) + fib (i-2)
返回 fib n
当然实际实现的时候因为用 array 坑爹,可以用几个变量 a、b、c 之类的进行替换。
这样的话每个 fib 只需要计算 1 次。计算 fib(n) 基本上是线性时间。 那个递归基本上是平方时间。
也就是 C 语言里用迭代的写法做 fib,计算 fib(n) 的所需计算次数大概是常数 c×n 的级别,而他那个是 c×n^2
用某种语言最不擅长的方法来写代码,当然他就快速了***