这里写了一个讲究小而美和工具之间组合的全文搜索的方法。
主要用 fzf,一个效率很高对每一行进行模糊搜索的工具。你可以给它喂一堆任意的字符串,然后从中搜索。
比如用 fd 喂给 fzf 所有目录,然后发送给 cd 来快速跳转目录
# in .bashrc
fcd(){
cd $(fd --type directory | fzf)
}
如果我想跳转到位置比较深 workbench-scheme 下 racket 目录,只需要输入 很短的 wor rac 然后按回车就够了
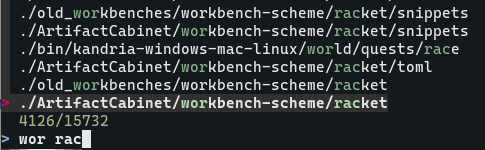
为了全文搜索,我们需要一个喂给 fzf 所有文件的文件名 + 行号 + 行内容的小脚本 cat-all.py
#!/usr/bin/env python3
import os,sys, subprocess
IGNORE_DIRS=[".git",".vscode","build"]
pwd=os.getcwd()
for (dirpath, dirnames, filenames) in os.walk(pwd):
if not any(ig in dirpath for ig in IGNORE_DIRS):
for file in filenames:
full_path=dirpath+"/"+file
relative_path=full_path[len(pwd)+1:]
mimetype=subprocess.check_output(["file","--dereference","--brief", "--mime-type", full_path]).decode()
if(mimetype.startswith("text")):
try:
with open(full_path,"r") as f:
for ln,line in enumerate(f,start=1):
if not line.isspace():
print(relative_path,"|",ln,"|",line.strip())
except:
print("[FAILED] ",full_path, file=sys.stderr)
然后就可以这样寻找当前目录下以前写过的所有的 hello, world
cat-all.py | fzf
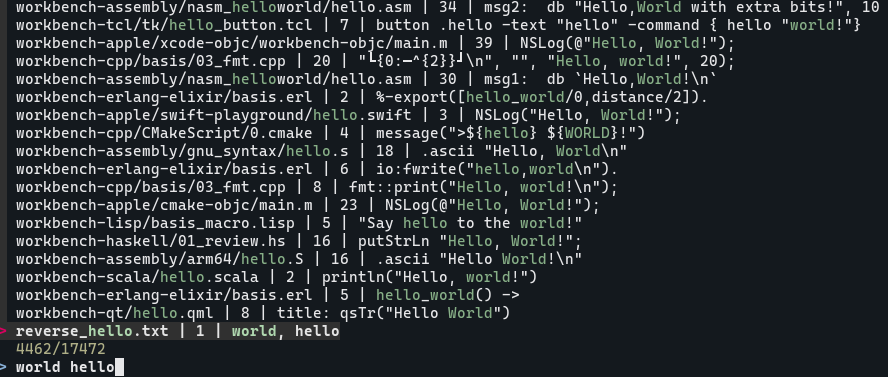
和 grep "Hello, World" 区别在于一些 hello_world,“Hello to some World”, “World Hello” 之类的也会被匹配到
如果想按回车直接打开对应的文件,只要把 fzf 输出的内容用 awk 截取第一部分传给 xdg-open 就行了
cat-all.py | fzf | awk '{print $1}' | xargs xdg-open &> /dev/null
据测量在我的电脑上这样搜索 80 万 行 左右的文本需要大约 12 秒左右的时间来索引,且过程中 fzf 占用 ~130mb 的内存。
有问题可以随便问,也欢迎各种指教。
