对许多人来说 pdf 格式的电子书最头疼的两件事 → 1) 每页都是没经过 OCR 处理过的图片 2) 没有目录。
以下这个批量加目录的方法我用好久了,见过我这么操作过的都想学一下,这里详细地记录以下,也方便以后有人再问的时候 :)
用到的软件是 pdftk pdftk-java / pdftk-java · GitLab 。linux 发行版一般都有这个这个软件可以直接安装。
pdftk 的用法就是:输出 (dump_data) pdf 的元信息 (data.txt),编辑以后,重新倒入 (update_info) 到 pdf 文件里面
主要是这两条命令:
pdftk [my.pdf] dump_data > [data.txt]
pdftk [my.pdf] update_info [data.txt] output my2.pdf
在第一条命令输出的 data.txt 里面加入如下的内容,然后通过第二条命令就可以创建新的目录条目
BookmarkBegin
BookmarkTitle: name
BookmarkLevel: level
BookmarkPageNumber: page number
另外电子书的第一页通常是封面,紧接着的是其它的东西。但是书里面标注的页码的第一页往往后面的某页。
PDF 支持把页码标注成其它的格式 (page_labels),第一页标注成 cover,第二到第十页标注成罗马数字,然后从第十一页标注成 1,2,3,4,5,6…
# 把第一页标注成名字为 cover 的非数字 (NoNumber)
PageLabelBegin
PageLabelNewIndex: 1
PageLabelStart: 1
PageLabelPrefix: cover
PageLabelNumStyle: NoNumber
# 从第二页 (PageLabelNewIndex) 开始标注成小写罗马数字 (LowercaseRomanNumerals)
PageLabelBegin
PageLabelNewIndex: 2
PageLabelStart: 1 # 从数字 1 开始数,如果这里变成 3 => 起始的罗马数字会是 iii
PageLabelNumStyle: LowercaseRomanNumerals
# 从 {true start page} 开始用普通的数字标注
PageLabelBegin
PageLabelNewIndex: {true start page}
PageLabelStart: 1
PageLabelNumStyle: DecimalArabicNumerals
对于一本书,这种手动添加的方法会很慢,下面是一个小脚本来半自动化。
由于电子书 100% 可以搜索到这种格式的目录 编号 标题 页码。如果搜索不到,也可以直接从书里面复制。


复制粘贴一下,调整成这种格式
14
I: Reduction Semantics 1
1 Semantics via Syntax 5
2 Analyzing Syntactic Semantics 13
3 The λ-Calculus 23
4 ISWIM 45
II: PLT Redex 201
11 The Basics 205
12 Variables and Meta-functions 217
13 Layered Development 227
14 Testing 237
......
第一行是对于人类,而非 pdf 格式来说真正的第一页
后面根据行首 tab 的数量来决定目录的层级
每行后面的数字是页码
然后用这个小脚本 toc-gen.py
#!/usr/bin/env python3
#
# Usage
# toc-gen.py < edited-toc.txt
#
def make_offset(off: int):
if off > 1:
print("""PageLabelBegin
PageLabelNewIndex: 1
PageLabelStart: 1
PageLabelPrefix: cover
PageLabelNumStyle: NoNumber""")
if off > 2:
print("""PageLabelBegin
PageLabelNewIndex: 2
PageLabelStart: 1
PageLabelNumStyle: LowercaseRomanNumerals""")
print(f"""PageLabelBegin
PageLabelNewIndex: {off}
PageLabelStart: 1
PageLabelNumStyle: DecimalArabicNumerals""")
def make_bookmark(t: str, l: int, p: int):
print(f"""BookmarkBegin
BookmarkTitle: {t}
BookmarkLevel: {l}
BookmarkPageNumber: {p}""")
if __name__ == '__main__':
offset = int(input())
make_offset(offset)
while True:
try:
line = input()
if not line.strip():
break
except EOFError:
break
title = " ".join(line.split()[0:-1])
n_of_tabs = len(line) - len(line.lstrip())
page = int(line.split()[-1])
make_bookmark(t=title,
l=n_of_tabs + 1,
p=page + offset)
来获取这些内容,把这些内容粘贴到 [data.txt] 后面,然后再用 pdftk 的第二条命令
PageLabelBegin
PageLabelNewIndex: 1
PageLabelStart: 1
PageLabelPrefix: cover
PageLabelNumStyle: NoNumber
PageLabelBegin
PageLabelNewIndex: 2
PageLabelStart: 1
PageLabelNumStyle: LowercaseRomanNumerals
PageLabelBegin
PageLabelNewIndex: 14
PageLabelStart: 1
PageLabelNumStyle: DecimalArabicNumerals
BookmarkBegin
BookmarkTitle: Reduction Semantics
BookmarkLevel: 1
BookmarkPageNumber: 15
BookmarkBegin
BookmarkTitle: Semantics via Syntax
BookmarkLevel: 2
BookmarkPageNumber: 19
BookmarkBegin
BookmarkTitle: Analyzing Syntactic Semantics
BookmarkLevel: 2
BookmarkPageNumber: 27
BookmarkBegin
BookmarkTitle: The λ-Calculus
BookmarkLevel: 2
BookmarkPageNumber: 37
BookmarkBegin
BookmarkTitle: ISWIM
BookmarkLevel: 2
BookmarkPageNumber: 59
BookmarkBegin
BookmarkTitle: An Abstract Syntax Machine
BookmarkLevel: 2
BookmarkPageNumber: 79
BookmarkBegin
BookmarkTitle: Abstract Register Machines
BookmarkLevel: 2
BookmarkPageNumber: 103
BookmarkBegin
BookmarkTitle: Tail Calls and More Space Savings
BookmarkLevel: 2
BookmarkPageNumber: 121
BookmarkBegin
BookmarkTitle: Control: Errors, Exceptions, and Continuations
BookmarkLevel: 2
BookmarkPageNumber: 129
BookmarkBegin
BookmarkTitle: State: Imperative Assignment
..............
Bingo! 这下舒服了 :)
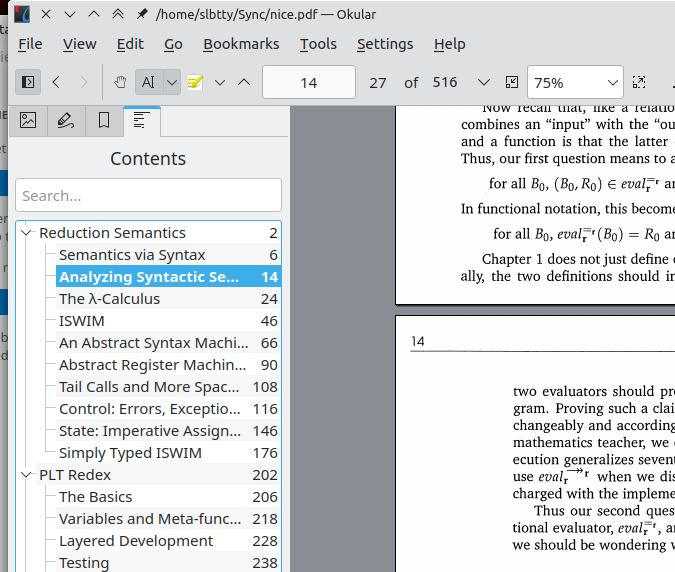
Ref:
adjust logical & real pdf pages
pdftk’s guide on toc
SEO keywords: Ubuntu Debian Arch Linux pdftk pdf 目录



